|
|
|
|
Important notice: The CSA web site was re-designed in August of 2010. Some documents then available were out of date; so they were not included in the re-design and were not updated. This is one of those documents. Information about dates of posting and revision remains here, but there will be no revision of any kind after August, 2010.
Database materials in particular have been superseded by the database chapter in Archaeological Computing.
Although many archaeologists are not using computers, most would now agree that computers are crucial to the record keeping and analytic work of an excavation. The organization of the data recorded, however, can have profound effects on the analytic possibilities and on the excavator's ability to control the information. Therefore, the design of the database system employed at a site is extremely important. (For a database concerned with the pottery from an excavation, after analysis, see the Lerna IV database adapted from J. B. Rutter's The pottery of Lerna IV by CSA's Susan c. Jones and Harrison Eiteljorg, II. This database is not complete, but the data for 365 items and the documentation for the design are available through this Web page.)
I do not believe that any single database design will solve the needs of all excavators. Indeed, I would argue that few excavators will agree to use any particular database design, no matter how good it may be for others. Nonetheless, there are certain common problems and common approaches that work well. In particular, the complexities of the relationships between and among the physical objects/contexts/circumstance encountered in an excavation are crucial; those relationships must be clear to users of the data. But the temptation is to simplify the database system in order to keep down development time and expense. I hope that the following will help archaeologists to understand how information can be handled so that they can better understand what to demand from the computer geeks who will work to construct their on-site systems.
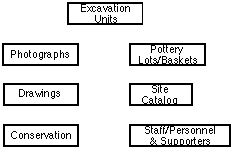
There is a temptation to think of data in more or less unrelated groups, tables of information about excavation units, pottery baskets, catalog items, personnel, photographs, drawings, and conservation work. Thus, in the following diagram, each box may be thought of as a repository for information in tabular form; the label indicates the subject of the information stored in the box. Each box would contain facts about the appropriate items. For instance, the photographs box would have a table containing negative numbers, descriptions of the subjects of the photos, the photographers, technical information about the photos, and so on.
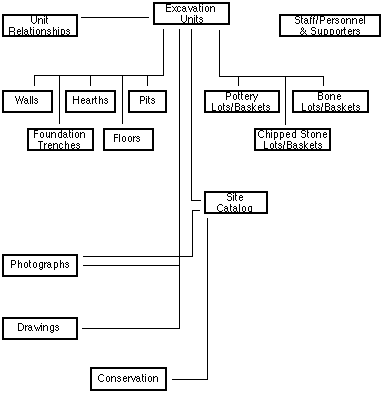
Those boxes or tables of data, however, must be more numerous, and the data must be more carefully categorized in order to handle the complexity of archaeological information. For instance, excavation units that are walls differ markedly from those that are floors from those that are pits in terms of the information stored. Each must have its own unique set of data items, but there are some data items in common. For instance, all excavation units have identification numbers, dates of excavation, specific excavators, etc. But walls have constituent materials, block or brick sizes, and so on, while pits do not. So, in the diagram that follows here, there are many more boxes or data tables than in the first one. Though there might be more still, this diagram gives an idea of how many different groups of information there might be.
In addition, the tables must be related to one another if the information in them is to be very useful. So, for instance, the general information about excavation units must be related to the information about walls, pits, or other individual units - and the relationships must work in both directions. The lines in the diagram indicate some of the connections between groups of data items.
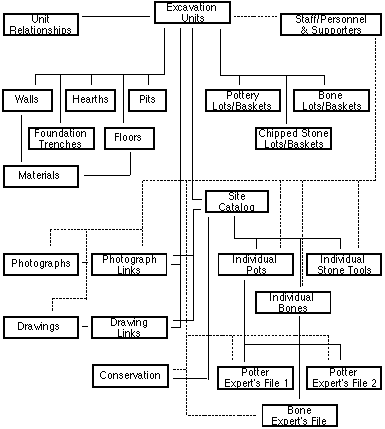
The real situation in the field is yet more complex. Tables must be related to one another in a multitude of ways, and the ways will differ from site to site. But the general principle is that the information should be stored in ways that permit the most accurate recording of the information, the most thorough recording of the relationships between and among information items, and the most complete recording of the true complexity encountered. So, for instance, in the next diagram, personnel are connected to virtually every information category so that one may know who did and recorded what.
You may also notice boxes for information called photographic links and drawing links. Tables like these are necessary to make certain that adequate information is recorded - and recorded in efficient ways. For instance, a photograph may include many objects or several excavation units. So, to be certain that all subjects of a photograph are noted, one must list all the objects or trenches or whatever. But, in the standard database, it is very inefficient to provide for a possible ten or twelve objects per photo - and a possible ten or twelve photos per object. It is far better to provide a simple list that serves as a kind of index to relate the photos to their subjects. In reality, a great many of such linking files may be required.
There are also some important reasons - both practical and theoretical - to try to separate observations from hypotheses when recording data. We often, for instance, consider the judgment that a given excavation unit belongs with a specific phase of a site to be an observation. Of course, it isn't; it's a hypothesis based on observations. Yet most would record the phase with other data about the excavation unit as if that were an observation. The theoretical reason for not doing that, of course, is to maintain the distinction between observations and hypotheses. The practical reason is also important. Once a phase has been recorded, it is very difficult to consider alternatives - something that automation should make very easy. On the other hand, if phases (and structural combinations for buildings) are recorded separately, it is possible to record a number of possibilities simultaneously, to examine alternates, to propose alternate scheme, and so on. Indeed, it is possible for another scholar to come along twenty years from now and link such a scheme to the data without altering the original data at all.
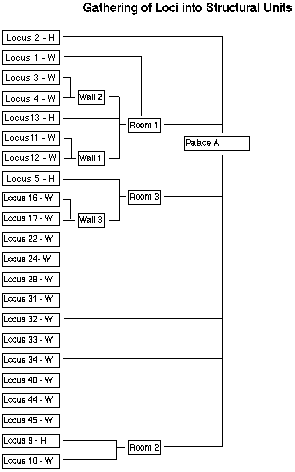
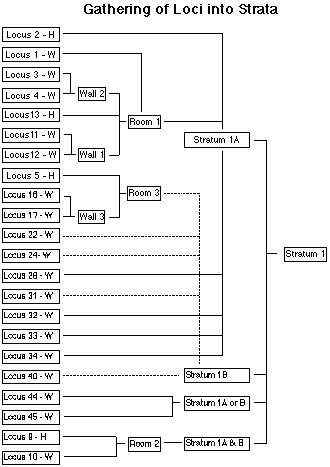
The following diagram shows the result of one such organizational system that separates strata designations from excavation unit (locus) information. A data file external to the observed information files contains just lists of relationships - Locus 3 - W is part of Wall 2, for instance. Similarly, Wall 2 is part of Room 1, and Room 1 is part of to Stratum 1A. The hierarchy is created from the specified relationships. But, if Room 1 were reassigned to Stratum 1B, one would not need to change the phase designation for the sub-units of room 1. More valuable to the excavator, Room 1 could be assigned to Stratum 1B* as an alternate without removing the assignment to Stratum 1A. That is, multiple, competing assignments could be maintained in such a system and multiple, competing hierarchies could be generated, permitting the excavator to consider a variety of possibilities as the analysis proceeds.
Similar organizational hierarchies can be created for structural relationships, and the last diagram shows how they might relate the same group of loci.