
|
|
|
|
Experiments like the one recently conducted with the Lerna pottery (see "The Lerna Database Experiment,") are, in part, experiments in electronic publication as well as experiments in database design. After all, one aim of such work is to try to determine whether or not a set of data presented electronically can be made as accessible and useful as the same data presented on paper. This is an especially relevant question today, because costs of publication are making it more and more difficult for scholars to get catalogs published. Costs for large catalogs are driving prices to such levels that fewer and fewer copies can be sold; that, in turn, means that fewer are printed, driving costs up yet further. Electronic publication of data sets in place of paper catalogs (note that this is not electronic publication of the discussion that accompanies the catalog) could be much less expensive and could also include color images rather than black-and-white, making better data available to a wider audience at a lower cost.
The Lerna experiment brought home both problems and potential gains for electronic publication of complex data sets.
The potential gains for users of electronic data are fairly obvious. First, there is better access to the data. Individual items can be presented in more complete form. Searches and reports can be generated automatically. The data can be queried in ways simply not possible with paper catalogs. Second, the user is free to ask questions not posed by the scholar who provided the data. Some questions may not be answerable, given the often idiosyncratic organization of data by individual scholars, but there will be many questions not posed by the original scholar yet still of interest to subsequent users and answerable from the data as presented. Third, data supplied in electronic form may be combined with other data to provide a larger corpus and new analytic possibilities. Finally, the cost of copying and distributing electronic files is almost nil, although the scholar or publisher supplying the data files may incur significant costs in documenting the files and preparing them for distribution.
The problems are also fairly obvious. First, to utilize the data to the maximum extent, a user must know and understand the original scholar's organizational scheme. It may be more difficult to understand some matters than others -or to understand their ramifications. While this may not be significantly different from the problems encountered with a paper catalog, the requirements may include some understanding of computers and database design as well as archaeological issues. Second, some computer skills are required of the user in order to access and use the data. Effective use requires, at the least, that the user know how to conduct searches and create reports with a database system. These are not difficult tasks, but they must be learned. Third, and most problematic, using data files requires a database program, and, in many cases, users must have the same program that was used to create the files if they are to gain full and complete access to the data.
The biggest hurdle is the last one. If users must have a particular program to access data in computer files, the utility of those files is compromised. This deserves a fuller discussion.
The simplest set of data that might be prepared for distribution in electronic form would be a single data table such as a list of items of a particular sort; for instance, I have made such a data table of the fibulae found in the so-called Midas tomb at Gordion (based on the information in the publication: Rodney S. Young, Gordion I, Three Great Early Tumuli (Philadelphia, 1981). Such a set of data would be most easily expressed on paper as a table, each row of the table would have information about a particular fibula, and each column would contain a certain kind of information, e.g., findspot, length, width, description, and so on. A sample of such a fibulae table, with only a few entries is provided in Table 1, and, in fact, there are several tables of fibulae in the Gordion volume.(1)
Table 1 - Fibulae at Gordion - a partial list of the fibulae from the so-called Midas tomb
| ID | Mate | Findspot | Group | Sub -group | Detail | Pin Side | Ht. | Length | Description | Plate |
| MM 255 (B 909) | MM 256 | Floor, at head of bed | XII | 9 | 3 studs on each block | L | 0.042 | 0.051 | Like MM 254; Spring-buttons radially striated. | |
| MM 248 (B 910) | MM 247 | Floor, at head of bed | XII | 9 | 3 studs on each block | R | 0.043 | 0.053 | Similar to MM 246; small cushions. | |
| MM 249 (B 923) | MM 250 | Floor, at head of bed | XII | 9 | 3 studs on each block | L | 0.042 | 0.049 | Similar to MM 248. | |
| MM 250 (B 929) | MM 249 | Floor, at head of bed | XII | 9 | 3 studs on each block | R | 0.04 | 0.048 | Similar to MM 248. Two large and eight small studs lost. | |
| MM 251 (B 919) | MM 252 | Floor, at head of bed | XII | 9 | 3 studs on each block | L | 0.042 | 0.052 | A small additional cushion between block and spring button | 78C |
| MM 252 (B 903) | MM 251 | Floor, at head of bed | XII | 9 | 3 studs on each block | R | 0.041 | 0.051 | A small additional cushion between block and spring button | 78D |
| MM 253 (B 918) | MM 254 | Floor, at head of bed | XII | 9 | 3 studs on each block | L | 0.041 | 0.0485 | Like MM 251, 252. Two large studs lost. | |
| MM 246 (B 928) | MM 245 | Floor, at head of bed | XII | 9 | 3 studs on each block | R | 0.0415 | 0.0515 | Similar to MM 244 | |
| MM 267 (B 941) | MM 268 | Floor,at head of bed | XII | 9 | 2 studs on each block | L | 0.047 | 0.0565 | Narrow cushions; small cushion between spring-button and nearest block. Two studs on spine of catch | 78G |
Such a data table is very easy to distribute. There are two nearly universal file formats for computer data tables, and any database program should be able to accept one of those formats. The file could be sent over the Internet or on a diskette. Once brought into a database program, the data could be searched quite easily; ordered by type, findspot, or any other category; and, in general, used to retrieve information according to the needs of the user as well as the scholar who prepared the data file. The user may need to know how to fetch the data table over the Internet, and the user must know how to use some database program in order to access the information. Nonetheless, a good deal of extra information and analytic power can be made available in return for rather little computer skill.
A more complex and sophisticated data set would consist of many separate data tables, each with a specific group of data items. In our example of a list of fibulae from Gordion, for instance, one of the pieces of information is the fibula type (group and sub-group). The types had been defined in an earlier publication: Christian S. Blinkenberg, Fibules grecques et orientales (Copenhagen, 1926). To provide the type definitions in computer form, we could construct another table with rows and columns; each row in this table would concern a particular fibula type, as defined by Mr. Blinkenberg, and the columns would contain the defining characteristics. Table 2 shows some of the entries from such a table. This table defines the types used in the fibulae table and, in that way, augments the fibulae table.(2)
Table 2 - Fibula Types as described inthe Gordion volume (information from the text put into table form).
| ID | Group | Sub- Group |
Group Characteristics | Sub-group Characteristics | Dating |
| 1 | XII | 9 | near semi-circular bow, hook catch usu. with spur or volute at base & grooves of some sort on outer face, moldings at bow end & often middle | flat x-sec of bow with bosses | mid 8th century to early sixth |
| 4 | XII | 7 | near semi-circular bow, hook catch usu. with spur or volute at base & grooves of some sort on outer face, moldings at bow end & often middle | cf. 13, but flatter bead, more prominent reels, no mid-bow version | 8th century |
| 5 | XII | 5 | near semi-circular bow, hook catch usu. with spur or volute at base & grooves of some sort on outer face, moldings at bow end & often middle | small, blocks at bow ends | late 8th into 7th century |
The original table, let it be called the Fibulae Table, with its information about the individual fibulae, would be implicitly linked to the definitions table through the use of common group names. For instance, XII, 9 is shown as the group for the Gordion fibula with the identification number MM 255; that group is listed in the second table (let it be the Types Table) with its appropriate defining characteristics. Using the two tables together, it is possible to look up a given fibula in the Fibulae Table, learn about its special characteristics, check the findspot, and then look in the Types Table to get the general characteristics of the group.
A more effective use of the two tables together can be obtained with most modern database systems. If the linkage between the two data tables is explicitly stated and has been activated, the database system can automatically link the individual fibulae in the Fibulae Table to the appropriate definitions in the Types Table. A user of this two-table data set could check any individual fibula and automatically see, along with the basic information about the fibula, the characteristics that define its type (see Fig. 1 for such a display of information, in this case complete with an illustration of the "typical" fibula of Type XII, 9). Such a relational database system allows the user to store data in a variety of tables (for the Lerna data set, we used 14 tables), making data storage much more efficient. In addition, utilization of data is much more effective and efficient for users.
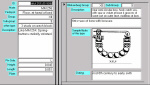 Fig. 1 - A form showing information about
one of the Gordion fibulae. This form includes information about the individual fibula,
information about the type, and a drawing of the typical Group XII, 9 fibula.
Fig. 1 - A form showing information about
one of the Gordion fibulae. This form includes information about the individual fibula,
information about the type, and a drawing of the typical Group XII, 9 fibula.As any data file can be transferred over the Internet or on a disk, this two-table set of information could also be sent to a potential user and loaded into his/her database program for use on his/her computer. However, if the transfer is in one of the standard, generic formats, the link between the files would not be included, because the generic data table formats cannot include such a link. That is, generic data files can easily be transferred, but any links between them are not part of the data files. The user of the data would be obliged to activate the link in his/her system before it could work, assuming he/she knew what the link between the files was.(3) Without the link, all the information would be there, but it would not be possible, for instance, automatically to pull up information about the appropriate type characteristics along with the individual fibulae, because the connection between the fibulae entries and the Types Table would not be known to the system. The user could, of course, display the two tables at the same time and switch from one to the other to find the defining characteristics of specific examples, but the computer could not automatically find the correct characteristics for display. Nor could a user manipulate the data as effectively without the links between tables.
A user who wants to utilize information in the two tables fully would need to connect the data tables with an explicit link. That would require knowledge of the specific link between the files and some added familiarity with database systems. The skill/experience required is not great; it is not trivial either. Those who approach the task without prior experience and also without confidence in computing skills would find it daunting.
Unlike data tables in common, generic formats, data tables from some database programs (in the format used by the program, not a generic format for data transfer) include the links between files as well as the data. With such files, the user would be able to access the data fully if he/she had the database program that was used by the creator of the files. That is, full access to data sets can be obtained easily if creator and user have the same database program.
To recapitulate, a single data table can easily be made available for use by others. There are no needs other than the actual data. More complex data sets, those involving multiple related data tables, require that the links between and among data tables be explicit and active if the data tables are to be utilized fully. Those links can be passed along with the data if the creator and the user of the data have the same database program, or they can be re-activated by a user in a different system if that user knows precisely what the links are and knows how to activate them in his/her database program.
There is another possibility that has not yet been mentioned. It is possible to use a database program to create data tables (with their links) and then to save not just the data tables but a set of files that includes the data tables and some of the functions of the database program. A user can load the files and run the system as if he/she had the original database program on his/her machine. (This is called a run-time version of the program; it can be run only with the data, not independently.) Naturally, there is a catch here. The new user cannot create new data sets, new forms, or new reports. Many other database features would also be unavailable. That may or may not be very important, depending on the nature of the data files and the skill of the user. An unskilled user would be able to do only those things planned by the creator of the files; a very skilled user could probably do anything he/she wished by using another database program (or even a spreadsheet) along with the run-time version of a database.
What does all this mean about electronic publication? It means, at the least, that sharing simple data tables is not particularly difficult, but sharing complex data sets is not an easy process. Users must have some computer skills to make maximum use of complex, multi-table databases. On the other hand, a user with only enough skill to import generic files and use them in his/her database system without connecting the files will still have at least as good a resource as a paper catalog with the same information. (I should comment that this comparison omits any discussion of the merits and difficulties of carrying a computer compared with the merits and difficulties of carrying paper catalogs, whether one is going to an excavation or a laboratory.)
Consider our list of fibulae. The electronic tables - without links - provide the user with information about the fibulae and with the characteristics of the fibula types, though each table of information would be separate. In a paper version, a similar situation would hold - tables with information about the fibulae and characteristics of the fibula types elsewhere. There are few differences between the paper version of the fibulae tables and the electronic one if the data tables are shared without their links, but the Fibulae Table is much more useful than its paper counterpart, since it can be sorted and re-ordered. If the links are included, the electronic version is more clearly preferable, because the defining characteristics can be called up with the fibulae, and other analytic capabilities are made available as well. For example, a user could search the Fibulae Table for fibulae of a certain date, even though dates are indicated only in the Types Table.
Now consider the Lerna material. The catalog itself - one of the fourteen tables in the database - can be sent to users as a single data table. So can each of the thirteen subsidiary tables. Even if each table must be used separately, the result is at least as useful as the comparable parts of the paper publication, which include the same data tables (not necessarily in tabular form, to be sure). The data tables without the links between files are not as useful as the complete data set with all links activated, but they are still as useful as the paper version of the same information. In fact, these files, even as unconnected files, are probably more useful than their paper counterparts, because each can be searched, ordered, and queried. Of course, the utility of the files is dependent upon the user's computer skills.
Given the issues just discussed, when should we begin publishing electronically? Should we publish data sets, run-time versions of databases, or . . . ? When should we start to expect that users can utilize data files as they can paper catalogs? What standards should we try to encourage to make the use of electronic files easier? These and other questions remain unanswered, but experiments like the Lerna database do help us at least ask the right questions - even if they do not lead to easy answers.
-- H. Eiteljorg, II
To send comments or questions to the author, please see our email contacts page.
For other Newsletter articles concerning the use of electronic media in the humanities, or issues surrounding the use and design of databases, consult the Subject index.
Next Article: Minnesota Archaeological Researches in the Western Peloponnese
Table of Contents for the Spring, 1998 issue of the CSA Newsletter (Vol. XI, no. 1)
 Table of Contents for all CSA Newsletter issues on the Web
Table of Contents for all CSA Newsletter issues on the Web
(1) The various tables presented in the Gordion volume were combined into a single computer data table. Once combined, the fibulae could be grouped according to the criteria used in the publication so as to create identical groupings of fibulae, but they could also be grouped according to any other criteria that might be desirable for a given purpose. The tables in the Gordion volume are very helpful, but the combined table in computer form is much more useful. Return to text.
(2) Each type could be defined in the fibulae table, but that would be very inefficient, since the information would be repeated for each fibula, and any change in a type definition would have to be entered for every fibula of that type. This Types Table is not only more efficient for this specific use, it also could be used with any other table of individual fibulae, whether from another tomb at Gordion, another site, or a museum. Return to text.
(3) This is one example of the kind of documentation that must be passed to potential users along with the data tables. There are many other pieces of information that are equally important. Return to text.