
|
[This article has been adapted from a paper presented at the 2007 CAA conference in Berlin. The theme of the conference was "Layers of Perception."]
When I first started building CAD models in the mid-80s, I did so to help myself understand the older propylon, the archaic entrance structure to the Athenian Acropolis that I had re-excavated in 1975 - and to help with reconstructing the missing portions of it.
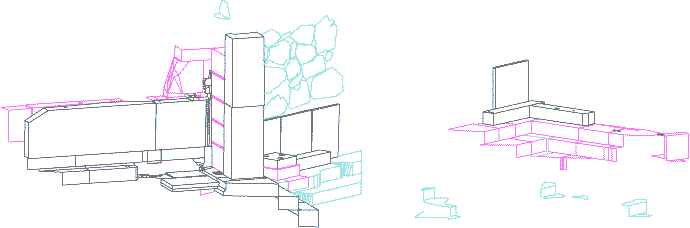
Figure 1 - The in situ material from the older propylon, 3D view.
The remains had been examined by others, most especially William Bell Dinsmoor, Jr., who had published his ideas about the entrance area shortly before I started using CAD. Though I was convinced that he was quite wrong, I realized that having his ideas present in published form meant that I needed to include his ideas about the reconstructed entrances as well as my own in any scholarly model of the early entrances to the Athenian Acropolis. That is, a complete record of the entrance sequence had to include Dinsmoor's views of the missing portions as well as my own because they were a part of the full scholarly record. Honesty compels me to add that, having Dinsmoor's reconstructions in the model also made it easier for me to show how they were wrong.
I created layers in the CAD model for the plans of each of Dinsmoor's early building phases as well as my own. I did not create 3D versions of Dinsmoor reconstructions because I did not have enough detail about his reconstructions to do so.
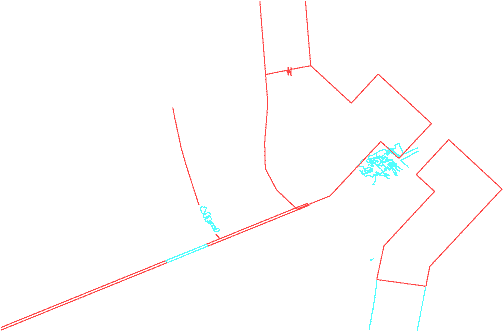 | 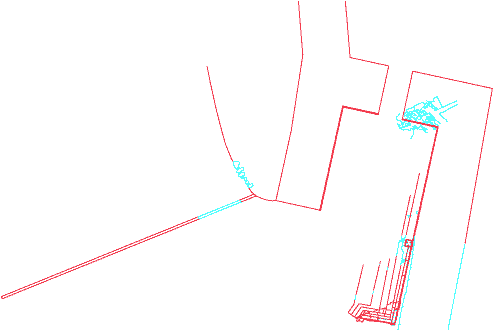 |
Figure 2 - Plan view of my proposed first archaic entrance based on the older propylon remains (left) and Dinsmoor's proposal (right).
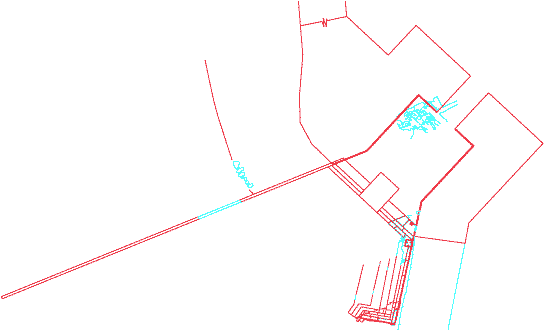 | 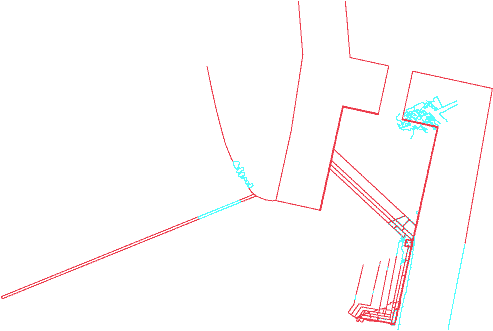 |
Figure 3 - Plan view of my proposed second archaic entrance based on the older propylon remains (left) and Dinsmoor's proposal (right).
Since my layer-naming scheme allowed layers to be searched as if using a database search, I did something with that CAD model in the 80s that I want to recommend for all databases today. What I did with that CAD model was very simple: I maintained in one computer file the competing, incompatible, and irreconcilable ideas of two scholars about the same remains. Those two ideas remain "alive" today, by which I mean that there are still adherents of both views.
Issues like this are common in archaeology - where there are on-going disputes and no way to settle them, once and for all, because the evidence is insufficient.
When I put into that CAD model the geometry of the in situ remains, the geometry of my reconstructed parts, and the geometry of Bill Dinsmoor's reconstructed parts, I knew that, along with the simpler and more straight-forward information about what was found (much of which, to be sure, had been simplified of necessity to model the ancient blocks) I needed to include all the interpretive portions of the model - the reconstructions I was suggesting and those of Dinsmoor - for the sake of anyone using the model.
When we put information into a database, the situation is similar. Some of the data is relatively simple and straight-forward - measurements, coordinates of findspots, labels of contexts, and so on. Some of it is simplified for convenience. And some of that information -- more of it than we might want to acknowledge -- is interpretive. Even so basic a matter as the style designation for a given pot is not, after all, engraved in stone, though we might like to think so. Despite the obvious nature of this situation -- the inclusion of interpretive information in databases -- we have a tendency to treat databases as static collections of simple and incontrovertible facts. Concerns about terminology, access systems, archival preservation, and metadata are common, but worries about the reliability of the data themselves are rarely encountered. We unconsciously take a positivist attitude toward our data, presenting data files as closed systems for examination rather than living, changing expressions of our knowledge at a particular moment in time. In fact, the theme of this year's CAA conference expresses my concern precisely: "Layers of Perception" can be taken to be layers of understanding that may or may not be compatible.
Please do not misunderstand. I am not suggesting that we have huge quantities of inaccurate data in our databases. I am saying that we have many, many interpretive statements masquerading as factual ones. Meanwhile, I see no apparent concern about that or the consequent need to provide some form of corrective action. I am also not saying that this is a problem when the data exist in a place and form allowing only limited access by scholars on a particular project. However, data sets that are meant to provide more open public access over the internet are a different matter. If access is relatively open, as it is with data sets on the web, there is a different level of responsibility that falls on the supplier of the data. Finally, I am also saying, explicitly, that notes in a miscellaneous field will not suffice. We must not relegate to an unsearchable nether realm the ideas and interpretations that we do not accept. All differing interpretations should be turned up by searches, whether the searcher knows there are debates or not.
I want to be clear that I do not see this situation as, in any way, the result of conscious attempts to exclude or simplify. Rather, I think we have been focused on other issues - data structure and access, archiving, presentation, and so on. It may also be that we are still thinking in terms of paper publications; we present what we know and do not take responsibility for changes.
My CAD model is, to anthropomorphize, quite happy to hold two incompatible views of the older propylon, and it would be no more distressed to have a dozen different views. Any database should be equally content to have within it various interpretations and to offer them all up to anyone seeking information. That is my simple message here. Databases intended for wide access should be structured to accommodate multiple interpretations of all those "facts" open to interpretation, to permit scholars to add their views to those already stored, and to offer up all in response to queries.
Another example: the Phrygian site of Gordion. The original excavator assigned the clear destruction layer at Gordion to the action of Herodotus' fabled Cimmerians at the very beginning of the seventh century B.C.E. Decades of work at Gordion has taken that destruction date as a basic piece of data. Unfortunately, that date now seems to be quite wrong. In fact, the destruction level is now seen to be the result of Assyrian attacks at a date near the end of the ninth century B.C.E.
How can these discordant interpretations of the basic Gordion chronology be dealt with?
The point here is not the chronology of Gordion, a topic on which I cannot speak as an expert. Nor is it my concern with Bill Dinsmoor's views of the older propylon. The point is that the archaeological record is replete with errors and misunderstandings that have been changed only over time such as the Gordion destruction level date; there are also disagreements that may remain unresolved indefinitely such as the competing views of the older propylon. Public data sources need to be constructed with this situation in mind - to be changing, not static, expressions of our knowledge.
There are important impediments to recognizing and dealing with this issue. First, as I've already said, we all tend, implicitly, to accept a positivist view of archaeological data. We may not believe that we have all the right answers today, but we think that a) there are right answers and b) we will find them eventually. This is especially the instance when a data set is handed off to a repository for archival preservation and, at the same time, public access. To the persons responsible for archiving, the data are complete as received; the adequacy and accuracy of the data were the responsibility of those who gathered, entered, organized, and stored the information.
I don't think that positivist view is accurate. Many things must remain beyond our knowledge and, as a consequence, in dispute. The date of the eruption of Santorini/Thera is a good example, with some thinking the issue settled and others insisting that it is not, even today. But perhaps the fact that scholars continue to debate the dates of two on the four great buildings of the Periclean Acropolis is more telling. Despite long and intensive study, the dates remain uncertain for the Erechtheum and the Nike Temple.
Second, it is unclear how best to expand the record when necessary - especially when the issue is not error but disagreement. I am willing to assert that this is not an insoluble problem but that there is no single solution. In some cases, we may need to add child tables (perhaps many of them) to existing tables. In other cases it may be better to use shadow tables that duplicate disputed rows while adding alternate interpretations. There are other solutions as well. I included alternates in a CAD model without giving it a thought.
In any case, to the extent that information in publicly accessible databases is contested, there must be ways to adjust the record so that nuanced complexity replaces lock-step simplicity. Note that I avoided saying anything about changing or replacing data or fixing errors. I avoided those terms because I do not think the record should be corrected; it should be expanded. New data should be added to existing data so that anyone looking at the files tomorrow, in a decade, or in a century can see all the thinking about the issues involved and can see what views were put forward at a certain time and later rejected, what views remain viable, and what views are taken to be accurate. Some of those "incorrect" views may, in the fulness of time, return to be seen as correct - or correct again. The resulting record would not only be more full and complete, we would all gain from the collected wisdom of many, not only those responsible for creating data sets but those who, standing upon the shoulders of their intellectual ancestors, help to make the record ever more accurate and complete - but, alas, never without the potential for improvement.
Searches on the net have shown one project that seems to acknowledge this problem - the OpenRecord project (www.openrecord.org) - but its real concerns seem to lie with open source software issues. Similarly, OpenContext project (www.opencontext.org) comes close to these idea with its tagging, but the emphasis is quite different.
At any rate, I am not concerned here with the tools that are used to store data and make them accessible to others: MySQL, PostGreSQL, Access, FileMaker, OCHRE, or whatever. What I do care about is making the record full, open, complex, nuanced - and evolving. When the excavator says that a given wall is part of room 1 of building 2 of phase 3 but a careful student has argued that the wall and room belong to building 3 of phase 4, I want all that information to be in the database if the data set is, in any sense, public. That means, of course, that I want all of us to build databases so that multiple competing views can be honored - and to make adding information to those databases as easy as possible.
Those multiple, competing views need to be tagged with the names of their proponents and the dates of their entry, and it may even be reasonable -- at least in some cases -- to tag the "standard" view so that a naïve user knows which of the competing entries is most widely accepted. But, as data are more and more widely shared on the net, I do not believe that it is legitimate to ignore or suppress the minority view(s).
Since I am agnostic as to database management systems, I will not offer here a specific database design. I will simply say again that there are many ways to attack the problem. Alternate views should be entered, stored, and retrieved easily.
The result of this process, a result achieved, I believe, in my CAD model of the older propylon, is data sets that gain strength and value from the inclusion of the best kind of peer review and involvement: different opinions honestly expressed and readily accessed together.
I should point out that I am not proposing a Wiki approach here. I do not believe that we have an obligation to permit uninformed people to add their opinions to our data sets. I do believe that any reputable scholar should be able to augment a data set so that the result is not simply one scholar's view but the view of many who have studied the material carefully. We all benefit when we treat our knowledge base as the evolving sum total of our collective wisdom rather than just one person's opinion.
My concerns are well summarized by a comment made by America's best-known humorist, Mark Twain. He said this: "It ain't what you don't know that gets you into trouble.
It's what you know for sure that just ain't so."
As we move into the world of the Internet, we simply cannot afford to ignore the essential truth of that comment. We need to provide fuller and more complex versions of our data so that users are not misled by what we "know for sure."
The last was paragraph designed as the close. It had the pithy quote and the general wrap-up. However, the first part of this paper has a kind of corollary that I want to discuss briefly. I have indicated that we need to make data in large, public data sets more nuanced and complex and that to make that happen, scholarly peers should be able to augment the record. I want now to take that one step further and argue that metadata need to be more full and more open to augmentation by users. I am especially concerned about image metadata because I have recently spent time looking at the access systems for large image repositories. (See Harrison Eiteljorg, II , "Image Repositories: Works in Progress," CSA Newsletter, XIX, 3; Winter, 2007; csanet.org/newsletter/winter07/nlw0703.html.)
That examination of repositories convinced me that image metadata is desperately in need of expansion. Here the need is not only dealing with disputed information, it is a desperate need for more information. When we look at images on the web today, we find some with only the subject matter defined, some with no information at all about the nature of the image (even the fact that something is a drawing, much less by whom and published where, when). Rarely is there really specific information about even the subject, e.g., date, time of day or year, viewpoint, etc.
As annoying as it is to find an image and feel the need for information not included, it is clear that having all the data at hand, much less spending the time to enter everything, is impossible. Most of the data is not available. Even when it is, putting it into the database may not be feasible.
It may be unrealistic to expect all the data to be available and entered. However, I think it is realistic to assume that expert users will willingly, even eagerly, augment the record. I think that expert users, given easy ways to do so, would be happy to augment the records about images being presented on the web. Furthermore, I think this is the only realistic way to make image repositories live up to their promise. The information is often as important as the images themselves.
So I will close with a plea for more bringing scholars into the process of augmenting data on the web in as many ways as possible. Those who are building data or image repositories must, I repeat, must, find ways to let expert users augment the data they have. Only some open process to permit that can make the promise of large data repositories be a reality.
Since the foregoing was presented as a paper, the discussion that followed should be described for what it adds. People were concerned about two issues: how the augment the record and how to decide/limit who might be permitted to have access for this purpose.
I was obliged to admit that I had ducked the last question and that I had no good answer to offer. One suggestion was members of professional organizations. That seemed a good idea, but there was no suggestion that received universal approval. There are certainly good scholars who possess minimal paper qualifications.
I also ducked the question of how to accomplish this process, but I did so because I do not believe there is a single answer. Every repository and every data set will require a different solution. That is not a great answer, but I think it is an accurate one.
-- Harrison Eiteljorg, II
For other Newsletter articles concerning CAD, on the use and design of databases, or <the use of electronic media in the humanities, consult the Subject index.
Next Article: Publishing 3-Dimensional Objects
Table of Contents for the Spring, 2007 issue of the CSA Newsletter (Vol. XX, no. 1)
 Table of Contents for all CSA Newsletter issues on the Web
Table of Contents for all CSA Newsletter issues on the Web
| CSA Home Page |