

| Vol. XXIII, No. 2 | September, 2010 |
Articles in Vol. XXIII, No. 2
Publishing Data in Open Context: Methods and Perspectives
Getting project data onto the web with Penelope.
-- Eric C. Kansa and Sarah Whitcher Kansa
Digital Antiquity and the Digital Archaeological Record (tDAR): Broadening Access and Ensuring Long-Term Preservation for Digital Archaeological Data
A new and ambitious digital archaeology archive.
-- Francis P. McManamon, Keith W. Kintigh, and Adam Brin
§ Readers' comments (as of 10/4/2010)
Website Review: Kommos Excavation, Crete
Combining publication media to achieve better results.
-- Andrea Vianello
The New Acropolis Museum: A Review
Some pluses, some minuses.
-- Harrison Eiteljorg, II
Aggregation for Access vs. Archiving for Preservation
Two treatments for old data.
-- Harrison Eiteljorg, II
Miscellaneous News Items
An irregular feature.
To comment on an article, please email
the editor using editor as the user-
name, csanet.org as the domain-name,
and the standard user@domain format.
Index of Web site and CD reviews from the Newsletter.
Limited subject index for Newsletter articles.
Direct links for articles concerning:
- the ADAP and digital archiving
- CAD modeling in archaeology and architectural history
- GIS in archaeology and architectural history
- the CSA archives
- electronic publishing
- use and design of databases
- the "CSA CAD Layer Naming Convention"
- Pompeii
- pottery profiles and capacity calculations
- The CSA Propylaea Project
- CSA/ADAP projects
- electronic media in the humanities
- Linux on the desktop
Publishing Data in Open Context: Methods and Perspectives
Eric C. Kansa and Sarah Whitcher Kansa
(See email contacts page for the author's email address.)
1. Introduction
Archaeological research, as is the case with many areas of the humanities and social sciences, often takes place in the form of small projects. Archaeologists generate their own data, and these data recorded are typically selected to enhance their own research agendas and to fit with their styles of recording. Because of the small-scale, localized nature of archaeological data production, integrating information across archaeological data sets can be very difficult. While archaeological data integration is a commonly articulated goal for practitioners of "digital archaeology," data integration's inherent complexity, conceptual and theoretical difficulties, and the discipline's limited technical capacity, all work against integration.1
Nevertheless, though data integration is hard, it is still a worthwhile goal. Data integration can make search and retrieval of archaeological information easier. This can increase the speed and efficiency of routine research like finding comparative collections and materials. Data integration can also open new research horizons by enabling scholars to compare and analyze pooled data. This lets archaeologists see the whole picture, rather than only a fragmentary view.
Open Context aims to help make it easier to work with data sets from different projects. It provides a common foundation for data in the following ways:
- Machine-Readable Representations Diverse datasets, no matter what their origin, can be read and parsed by software.2
- Common metadata: Geographic, time, and standard Dublin Core3 metadata are provided for all data.
- Common query interfaces: Different datasets can be searched, browsed, and queried through a common set of tools and methods.
- URLs to individual "units of analysis:" Open Context provides stable Web links to individual units of analysis4 from every dataset. Essentially this enables database-like "joins" between Open Context content and content from other collections on the Web (see below).
Open Context's main goal is to make data more accessible and provide a solid foundation for future data integration. Different datasets in Open Context may still differ in terminology and vocabularies. This means terms like "sheep/goat" and "ovis/capra" are not automatically related by Open Context. However, once published with Open Context, these datasets will at least share some common metadata and can be found and accessed through a common set of human and machine interfaces. Mapping to Open Context still represents an important first step to facilitate future data integration. Users can also search within multiple projects and collections. With the right background knowledge, an informed user can formulate queries using these different terms to obtain results that they consider to be meaningful for comparison.
As discussed, Open Context does not try to solve all the problems of data integration, especially in a semantic sense. We believe data integration should be driven by researchers, their questions and their needs. That is, the way one would integrate data would depend on one's research questions and priorities. In addition, different research agendas will require different sources of data. In many cases, one may want to integrate Open Context data with data from a completely different source. Because of this last point, we are trying to make Open Context data easier to use with other data sources that may be distributed across the Web. Thus, we emphasize data portability with simple Web-services (presenting data in formats that software can parse) over elaborate tools for building ontologies that are required for complete terminological data integration. In doing so, Open Context makes it easy to present precisely defined sets of data in a variety of formats. This may make terminological integration more likely in the future, and it lets us publish data now, even though more comprehensive forms of data integration are currently less feasible.
Generating URLs for each archaeological data-point makes it easier to combine Open Context data with data from other sources on the Web. Open Context URLs link to observations of individual entities (sites, excavation contexts, artifacts, ecofacts) with a high degree of granularity5 For archaeological data, publishing a unique Web document for each significant observed entity (such as individual artifacts, contexts, sites, etc.) may offer the optimal level of granularity. Open Context offers links to observations (that are made by one or more persons and include a set of one or more descriptive properties) to locations and objects.6 Users or software, perhaps from another website where a query has begun, can run precise queries on Open Context to obtain lists of URIs that match analytically important criteria. In doing so, software or other websites may classify Open Context content according to their own ontologies (for an expanded discussion, see Kansa and Bissell 2010). Thus, publishing in Open Context facilitates use of other more elaborate approaches toward data integration.
2. Technical Background
As described above, Open Context's primary purpose is to publish archaeological data in a manner that facilitates reuse, including reuse that requires data integration. However, before we publish data in Open Context, the data must be properly annotated and prepared.
Open Context provides a -mapping tool, called "Penelope,"7 that assists Open Context editors through the process of uploading content into the system (Kansa 2007). To facilitate data import, Penelope guides editors and data contributors through a step-by-step process to classify each field in their legacy data table according to ArchaeoML, the schema at the core of Open Context. Each step has a manageable level of complexity and conceptual abstraction. Penelope provides immediate dynamic feedback that illustrates the effect of selected mapping parameters. The immediate feedback helps editors and contributors correct mis-mappings as they occur. At the end of the process, Penelope assigns a URI to each unique entity meaningful to the study (typically, sites, excavation contexts or individual artifacts and ecofacts). Penelope thus enriches datasets by providing a foundation for linking to other data sets. Over time, we hope this easy Web referencing will pave the way for others to further enrich datasets, perhaps by mapping data to more semantically refined ontologies such as the CIDOC-CRM (http://www.cidoc-crm.org/official_release_cidoc.html) or ontologies developed by Digital Antiquity's tDAR project (http://dev.tdar.org/confluence/display/TDAR/Home).
The Penelope import process involves a number of user-guided steps and software processing of source data. Users upload data in a table-by-table manner. Tables from relational databases are related through their "keys." These steps and processes include:
- Metadata Creation: Metadata to facilitate searches, information retrieval, and comprehension of contributed data must be created. For each project, Penelope requires an abstract, key words, approximate calendar date ranges, location information, additional notes and descriptions of fields. Penelope provides various forms for inputting these metadata.
- Schema Mapping: Penelope has several interface features to enable users to describe their source data in terms of the ArchaeoML data structure. In this way, each field in a given data table is classified as referring to the name of a location or object, a file name of a media resource, a person, a linking relationship (such as stratigraphic relations) or a descriptive property. Spatial containment relationships8 are also defined. Users may also identify which fields may describe other types of relationships such as stratigraphic relations between contexts or identify fields that describe people that played analyst or observer roles. This step is not necessarily "objective" and there may be multiple ways to map a given dataset to ArchaeoML. Schema mapping involves judgment calls and determinations about what mapping parameters make the most sense and would best facilitate information retrieval and comprehension in Open Context.
- Data Processing: Once the user has finished describing and classifying the fields of their data table, Penelope is ready to process the import. Penelope identifies unique entities in an import and creates records that relate these entities to each other in meaningful ways. While doing so, Penelope keeps a record of potential problems and errors (such as repeated values in keys or blank records). UUIDs (universal unique identifiers) are assigned to each individual location and object item, person, descriptive property, media resource, etc. These UUIDs will be used to create Web links for each observational entity imported. The ArchaeoML standard requires UUIDs for each ArchaeoML document. UUIDs are also useful because identification systems in different projects may occasionally collide. For example, there may be multiple "Locus 1" contexts in different projects, or even in the same project.
- Review and Editing: Once Penelope has finished processing an import, the user has an opportunity to review the results. Penelope offers interface tools to navigate an imported dataset and preview the results of an import as it would appear in Open Context. Editing tools are provided so that users can fix minor typological errors, edit or delete blank records, create additional notes or upload additional related media files. Sometimes the import results make little sense, in which case the user can undo the results of an import and try different import parameters.
- Publishing and Indexing: After all imports, reviews, edits, and metadata documentation, the editor can finalize the import by publishing the data in Open Context. Once posted into Open Context, the dataset is considered published and publically available.
2.1 How Penelope Works
Penelope's data processing software is very simple. First, it relies upon the data structures inherent in a researcher's uploaded table. A data table describes a matrix of meaningful relationships between individual cells defined by rows and columns. Figure 1 provides an example where the data table on the top of the figure contains information from a zooarchaeological analysis.
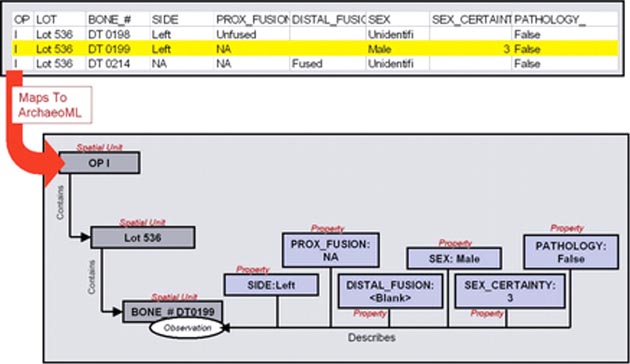
Figure 1. Example data mapping
(Click here for full-size image.)
The highlighted record contains information about Bone # DT 0199. Because the terms, "Left," "NA," "Male," "3," and "False" are in the same row, these terms relate to Bone # DT 0199. The column headings provide additional information about what these terms mean. In this case, the term "Left" refers to "SIDE."
To begin with, the Penelope user classifies the different fields in the data table according to ArchaeoML concepts. Some fields identify different locations and objects (or "spatial units" for short). In the example above, these fields are "OP," "LOT," and "BONE_#." Archaeologists often organize contextual units within hierarchies, and Penelope allows users to describe these hierarchies. In this case, "Ops" (excavation operations) contain "Lots" (contextual units), and lots contain bones.9 If these data came from a relational database, lots and ops may be further described on another table that can be imported with Penelope.
Other fields provide descriptive information, and these are considered "properties" in ArchaeoML. Properties are unique pairs of descriptive variables (in essence the type of description, observation or measurement being made) and values (individual instances of description). In our example, Bone # DT 0199's descriptive properties are SIDE:Left, PROX_FUSION:NA, SEX:Male, SEX_CERTAINTY:3, and PATHOLOGY:False. Penelope asks the user to indicate which location and object field is described by these property fields. By asking this, Penelope can make sure to associate these descriptive properties to bones, and not to lots or excavation operations.
Once the import parameters are given, Penelope then translates spatial containment relationships, property descriptions, and other relations from the source data. In doing so, Penelope generates unique identifiers for each defined entity. These entities include observations on unique locations and objects, people, descriptive properties, and media files. A complication sometimes arises in determining if a given location and object record is unique. Some excavation recording systems may have multiple contexts called "Lot 1," each in a separate operation, so that these records, in fact, describe distinct entities. Because of this complication, spatial context information is often needed to disambiguate between multiple entities sharing the same label. For instance, if there is a "Lot 1" contained in Operation 1, and another "Lot 1" contained in Operation 2, then Penelope will, as required, differentiate these contexts.
To reiterate, the Penelope user classifies fields in a data table and describes important relationships between those fields. This annotation can read something like the following examples:
1. "Items in 'LOT' contain items in 'BONE #' ."
2. "Values of 'SIDE' describe items in 'BONE #' ."
Once the user has finished annotating the data table, Penelope uses these annotations to guide its processing of the data. Each unique location and object is given a unique identifier that will be used to generate Web URIs. Penelope then associates the appropriate (as defined by the user) descriptive property for each location and object, person, and media file being imported. These identifiers and their links to each other and to descriptive properties are stored in a database. When a dataset is ready for public release, Penelope generates a document from the stored data. The document is then stored and indexed in Open Context.
2.2 Data Import
As described above, importing data through Penelope is a fairly elaborate process. Thus, Open Context is emphatically not a "Flickr for data." Instead, datasets undergo significant description and annotation, all driven by then need to facilitate information retrieval, comprehension and reuse. Because of these requirements, data imports typically need some oversight or guidance by people familiar with the underlying ArchaeoML structure used by Open Context. Penelope's moderate conceptual hurdles, together with the additional requirement for some quality control and proper documentation impose some difficulties on "user generated content" models. Research datasets have some inherent complexity. It is unlikely we can make Penelope easy enough to enable completely novice users to publish their own data without help. But since we believe some professional editorial control is important for researcher applications, Penelope's moderate level of complexity is quite manageable for Open Context's model of editorially supervised data publication.
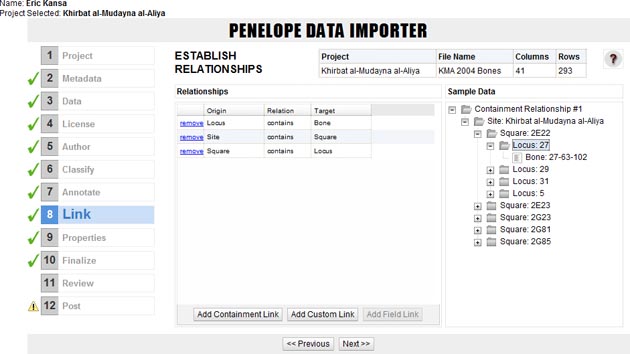
Figure 2. A screen shot of Penelope in use.
(Click here for full-size image.)
As we look to the future, however, mapping and importing data in Penelope will only get easier. We have now imported several datasets using various versions of Penelope and, in doing so, have refined Penelope with additional features to accommodate a wide range of needs. This development process has been lengthy, but now Penelope is a very capable application. Mapping and importing data in Penelope is now very fast, and even a complex dataset of multidisciplinary data contributed by several specialists can be mapped into the ArchaeoML data model with little trouble in under an hour. Metadata documentation and edits can take considerably more time, depending on source data quality and the amount of documentation provided by contributors.
In addition to refining the software, we are collecting a growing body of data on how archaeological datasets map to the ArchaeoML data structure. These data can be used in the future to automatically generate suggested import parameters, based on similarities seen with past imports. Autosuggestion already helps speed the process. For example, colleagues at the San Diego Archaeology Center have been trained to use Penelope. Their import parameters can be used over and over, so that they can soon publish their professionally managed collections data without intervention of Open Context editors.
Finally, we are always experimenting and trying new strategies to improve the interoperability of Open Context data. We are currently experimenting with Freebase.com's "Gridworks" application. This will enable us to reference external entities in the Freebase's community database. Though Freebase is a commercial project, its data are openly licensed and freely exportable. It can be useful to reference entities in Freebase because these entities may describe important widely shared concepts, such as the species "Ovis aries," or commonly used units of measurement, such as "weight in grams." Freebase mints stable URIs to each of these concepts, just as Open Context mints stable URIs ("Uniform Resource Identifiers," which on the Web usually equate URLs) to individual archaeological observations. By referencing URIs to Freebase's entities, we can define content in Open Context in unambiguous terms. Using Freebase's URIs will facilitate "joins" of Open Context data with data published by different sources.
3. Data Publication Guidelines for Contributors
Most archaeologists will care little about the technical aspects of importing data using Penelope, but will see editorial supervision as a critical concern in data publication. As discussed above, instead of adopting a "user generated content" model, Open Context models itself more along the lines of a journal, where content goes through some professional review and formatting (in this case, with Penelope) before publication. We welcome submissions and publication proposals. For researchers interested in publishing with Open Context, we have developed the following guidelines to prepare data for smooth publication:
3.1 Data Preparation
- Good Database Design: Good database design from a project's start makes eventual data publication easier. Normalization (removal of redundant information) helps to maintain data quality. Maintaining consistency is also important. For example, numeric data fields should contain only numeric data. If additional notation or explanation is required for some numeric information, these should go in other fields. Data validation (error checking) practices throughout data collection will speed data publication and help make the published data more valuable and easier to use by others.
- Clean-up and Edits: Publishing data in Open Context is a form of publication, but one that differs from journal articles or books. Because datasets are often fairly "raw," one should not expect compositional excellence in daily logs, database comment fields, etc. Spelling problems should be corrected, but heavy editorial effort on logs may not improve data usability too much. Because editorial attention is expensive, it should probably be focused more on improving more fundamental issues in data consistency, integrity and documentation. For instance, nominal values (terms used over and over again), such as the terms used to describe artifacts in a small finds database ("lamp," "coin," "spindle-whorl"), should be consistent (in terms of plurals, terminology, and spelling) to aid search and understanding. Identifiers for objects or contexts (such as "catalog #," "locus #"), especially those that have associated descriptive information should also be free of errors.
- Decoding: To speed up data entry, many people use coding systems as a convenient way to record data. However, these coding systems may be unintelligible without explanation. To facilitate understanding of a dataset, we require data contributors replace code with intelligible text before import.
- Description and Explanation: Each field of every dataset must have some narrative description to aid interpretation, even if only a sentence or two. Sometimes certain values in these fields should also be described, especially if data contributors employ terminology that is not widely used by their colleagues.
- Structural Relations: Archaeologists often manage their data in relational databases with complex structures. These structures need explanation so that editors can perform the proper queries to extract data. Specifically, we will need to know the primary and secondary (foreign) keys in each table.
- Locations and Objects: Open Context creates a separate web page (retrieved at a URL) for every location and object, person, and media file it publishes. It is important to let Open Context editors know which fields represent identifiers for different locations and objects (archaeological sites, archaeological contexts, survey tracks, artifacts, ecofacts). Ideally, some descriptive information should be made available for each identified location and object, including excavation areas or trenches, even if these descriptions are only in narrative form.
- Images and Media: Images and other media comprise an important component of archaeological documentation. Each individual media file must be clearly and unambiguously linked to one or more specific records in the dataset (such as records of excavation contexts, people, excavation log records, artifact records, etc.).10 The data contributor should prepare a separate table listing each image file name, an image description (if desired) and the number/identifier of the object or place the image describes.
- Abstract and Background: Each project should have a narrative abstract or background description. This should provide introductory information describing the project goals, key findings, as well as methods and recording systems. For large projects, contributors can also provide additional supplemental background descriptions of specialist analyses. These materials may be submitted in Microsoft Word (or similar) format.11
- People and Attribution: For citation purposes, every record in Open Context must be attributed to one or more specific person(s). This includes narrative passages, photographs, other media, and all items deposited. In some cases, certain database fields have records of different people who made observations and analyses. Ideally, the people identified in these fields should be identified by full name (not initials) and these names should be spelled properly. In other cases, entire data tables or datasets are created by a single person (such as a specialist). For each data table, contributors should provide a name and institutional affiliation for the person(s) primarily responsible for authorship.
3.2 Data Formats and Structures
Data for import should be in Microsoft Excel tables. The first row ("row 1") of the table should contain data field names (columns). The other rows should have the data records in the table, with each data record listed in a separate row. If contributors do not have Excel or cannot produce Excel spreadsheets from their databases, Open Context editors can generate Excel files from Filemaker, Access, and Open Office, as well as comma separated value files and tab-delimited files. It is best to extract image and other media from a database (if stored in binary fields) and store them as individual files.
The project abstract/background should be in Microsoft Word (or a similar format). Contributors may provide additional supporting or related documentation, such as PDFs of related publications, extended bibliographies in Word, and links to related web resources (such as descriptive project web sites, profiles of project participants on their institutional web sites or links to self-archived publications related to the dataset).
3.3 Location Information and Site Security
Open Context requires at least one geographic reference for each project. This geographic information should be the most pertinent location information useful for interpretation. This is usually the location of sites. Because Open Context makes all data freely and openly available, data contributors must consider site security issues associated with revealing location data. If location data represents a threat to site security, these data should not be revealed with great precision. Instead, sensitive location information should be only provided publicly at reduced precision. Users should be informed of this manipulation, and contact information needs to be provided for qualified researchers to obtain precise location data.
3.4 Copyright and Licensing
Open Context publishes open access, editorially controlled datasets to support future research and instructional opportunities. Thus, data contributors must make their content legally usable by others. To ensure legal reuse, we require that all content be released to the public domain or that contributors use Creative Commons (creativecommons.org) copyright licenses on their content. We strongly recommend users select the Creative Commons Attribution license. The Attribution license is easiest to understand and helps makes contributed data widely useful as possible. While we allow licenses that restrict commercial uses, we recommend against such restrictions. Such restrictions are inherently ambiguous and would inhibit important uses, such as inclusion of content in textbooks or even journals distributed through sales.
In the US, copyright applies to expressive works, not compilations of factual information. Therefore, Creative Commons copyright licenses are not appropriate for some datasets, especially those with limited "expressive" content. Datasets that are less expressive and have less authorial voice tend toward a more scientific and factual nature (i.e. those that mainly include physical measurements and adhere to widely used conventions in nomenclature and recording). These datasets should use the Creative Commons-Zero (public domain) dedication.
We encourage contributors to choose a single license to apply to the entire dataset; however, we can also assign different license choices to individual items. It is important to note that copyright and licensing issues are largely independent of scholarly citation and attribution. Professional standards dictate that all users properly cite data contributors even for public domain content, especially for scholarly uses. This professional norm of conduct works independently of the copyright status of content.
3.5 Peer Review
Open Context content must pass professional editorial scrutiny before it can be published on the Web. Open Context only accepts content from professional / accredited researchers, government officials, and museum staff. Contributors must be able to demonstrate adherence to appropriate legal, ethical, and professional standards of conduct and methodological rigor. In addition to these editorial controls, contributors may also request peer review of their contributions. If peer review is desired, we ask contributors to provide names and contact information for possible reviewers, as well as a brief description of the expertise needed to make informed judgments of their content. Content that passes peer-review will be clearly marked as such on Open Context.
4. Data Archiving and Preservation
Data preservation and ensuring the long-term persistence of citations represent tremendous institutional challenges. These challenges are well beyond the capacity of a small effort like Open Context. However, as in many areas, emerging distributed services and infrastructure can help data sharing efforts like Open Context meet such challenges. Open Context now draws on data preservation and curation services from the University of California's California Digital Library (CDL) as part of the library's participation in the National Science Foundation's DataNet initiative. These include:
- Minting and binding of ARKs ("Archival Resource Keys"): ARKs are special identifiers managed by an institutional repository. The CDL will help insure the objects associated with these identifiers can be retrieved in the future, even if access protocols such as "HTTP" change.
- Data archiving: The CDL also provides data curation and stewardship to maintain integrity of digital data and to migrate data into new computing environments as required.
The University of California provides Open Context with a strong institutional foundation for citation and data archiving. We will continually extend Open Context to take advantage of CDL data curation services as they expand and improve.
5. Estimating the Cost of Data Publication
The National Science Foundation this year will begin requiring grant seekers to submit a detailed Data Access Plan. Open Context offers a budget estimation form to help scholars prepare to meet their data sharing requirements (see http://opencontext.org/about/estimate). This form helps applicants budget appropriately for data sharing and archiving and generates text for use in their Data Access Plan. The text includes a description of interoperability, access, and archiving issues that help determine the scientific value of shared data.
6. Conclusion
Open Context publishes archaeological data to facilitate reuses, including reuse that requires more sophisticated forms of data integration. The publication processes outlined above add some extra value to "raw-data" to facilitate reuse. These processes take place under editorial supervision, which makes Open Context's model of data-sharing less like Flickr or blogging and more like mainstream academic venues such as this newsletter. We see the Open Context publication processes as a first step in a new life for archaeological data online. As described above, data integration is not an all or nothing affair. Open Context takes an incremental approach to the challenge of data-integration. Data currently published in Open Context are already useful (and used) for a variety of purposes, including instruction and identification of comparanda, even without reference to more elaborate ontologies. Future application of more sophisticated ontologies will make Open Context content even more useful for research. By making Open Context data portable and easy to use by third-parties, it is easier for other people to use Open Context data in exciting new ways. Thus, we see publication in Open Context as a first step in giving new meaning and value to old archaeological data.
-- Eric C. Kansa and Sarah Whitcher Kansa
Notes:
1. The fragmentation of the archaeological record across so many small projects, not to mention the inefficiencies and gaps in archaeological publication, make digital approaches increasingly necessary. An archaeologist who looks for related comparative material needs to find needles in multiple haystacks. Without digital data sharing and advanced search tools, this task becomes increasingly difficult. Return to text.
2. Open Context offers data in the Atom Syndication Format (a popular "standard container" for syndicating content across the Web. Atom is used widely for Web services that share query results across multiple applications), JSON ("Javascript Object Notation," a format widely used for making dynamic and interaction-rich Websites), KML (on open format used by GoogleMaps, GoogleEarth and other geospatial visualization applications), and most completely, ArchaeoML (the "Archaeological Markup Language," an XML standard for expressing archaeological data, first developed by David Schloen for the University of Chicago OCHRE project). Return to text.
3. Dublin Core is a widely used metadata standard. Although it is very simple and does not adequately describe content for specialized, domain specific applications, Dublin Core's widespread use makes cross-disciplinary content sharing easier. Return to text.
4. A "unit of analysis" in Open Context usually refers to an observation (made by one or more person) of a location or object. The same object may have multiple observations, and these could be referenced individually with their own hyperlinks. Different observations made on the same item by different observers (a context, artifact or ecofact) may make contradictory assertions. Thus, Open Context allows for disagreement and differences in opinion in archaeological descriptions. Return to text.
5. Granularity refers to the "size" of a resource. Finer granularity allows for more freedom in combining data into different assemblages and structures. Return to text.
6. An ArchaeoML "observation" can be expressed using the CIDOC-CRM. Most ArchaeoML observations can be described as CIDOC-CRM "attribution events" (concept "E13"). The people related who made ArchaeoML observations could be described using the CIDOC-CRM with CIDOC properties like "P39 measured," "P40 observed dimension," or "P41 classified." However, while possible, relating Open Context data to the CIDOC-CRM would require additional work by someone proficient in the CIDOC-CRM. Return to text.
7. Penelope consists of 100% open source components, including: MySQL, PHP, and DojoAjax. Return to text.
8. Spatial containment relationships in Open Context are somewhat loosely defined. A parent context, such as a site, can contain one or more children contexts such as excavation areas. Each area may contain loci, baskets and other contexts, which in turn, can contain individual ecofacts and artifacts. However, Open Context does not require any of these locations and objects to have associated geospatial (GIS) data. Return to text.
9. Penelope allows a user to describe spatial containment hierarchies of any depth. For example, the Petra Great Temple Excavations project in Open Context has a spatial hierarchies that is 4 levels deep, where "Areas contain trenches, trenches contain loci, loci contain sequence numbers, and sequence numbers contain artifacts." Another project, the "Dove Mountain Groundstone" project has a spatial containment hierarchy that is only 3 levels deep. Return to text.
10. Open Context permits "many-to-many" relations between media files and observations of artifacts, contexts, and other entities. Image hot-spots can be defined so that a portion of an image can link to a specific artifact. However, defining such hot-spots can be time-consuming. Because of these time-constraints, Open Context only lists links between media and observed objects. Return to text.
11. Open Context emphasizes data sharing using open, and non proprietary file formats. We accept MS-Word documents and Excel spreadsheets from contributors to make it easier to work with contributors. However, Open Context editors extract content from these proprietary formats and use open formats (XHTML, XML, CSV, etc.) for public dissemination and archiving with the California Digital Library. Return to text.
References:
Kansa, Eric (2007). "An Open Context for Small-scale Field Science Data," Proceedings of the International Association of Technical University Libraries Annual Conference (Stockholm, Sweden). http://www.lib.kth.se/iatul2007/abstract.asp?lastname=Kansa
Kansa, E. C., & Bissell, A. (2010). Web Syndication Approaches for Sharing Primary Data in "Small Science" Domains, 9, 42-53. Retrieved from
http://joi.jlc.jst.go.jp/JST.JSTAGE/dsj/009-012?from=CrossRef

All articles in the CSA Newsletter are reviewed by the staff. All are published with no intention of future change(s) and are maintained at the CSA website. Changes (other than corrections of typos or similar errors) will rarely be made after publication. If any such change is made, it will be made so as to permit both the original text and the change to be determined.
Comments concerning articles are welcome, and comments, questions, concerns, and author responses will be published in separate commentary pages, as noted on the Newsletter home page.